全网都在玩的生图模型,我用它把 iPhone 17 提前发布了
全网都在玩的生图模型,我用它把 iPhone 17 提前发布了最近,朋友圈和抖音小红书几乎被 Nano Banana 刷屏了。这个香蕉模型似乎要让 P 图这个词消失,直接给 Gemini 带来了一千万的新用户,火得一塌糊涂。
来自主题: AI资讯
7794 点击 2025-09-10 10:46
 搜索
搜索
最近,朋友圈和抖音小红书几乎被 Nano Banana 刷屏了。这个香蕉模型似乎要让 P 图这个词消失,直接给 Gemini 带来了一千万的新用户,火得一塌糊涂。

一年前,Google 在 AI 赛道上还是「追赶者」的形象。ChatGPT 席卷硅谷时,它显得迟缓。 但短短几个月后,情况突变。 Gemini 2.5 Pro 横扫各大榜单,「香蕉」模型 Nano Banana 让生图、修图成了轻松事;视频模型 Veo 3 展示了物理世界的理解力;Genie 3 甚至能一句话生成一个虚拟世界。
谷歌回归搜索老本行,这一次,它要让 AI 能像人一样「看见」网页。 这是谷歌前不久在 Gemini API 全面上线的 URL Context 功能(5 月 28 日已在 Google AI Studio 中推出),它使 Gemini 模型能够访问并处理来自 URL 的内容,包括网页、PDF 和图像。

在图像生成上,Google 其实已经有 Imagen 4 这样的文生图模型,为什么 nano banana 最后还是由 Google 带来的?但这确实不是偶然或者瞎猜的,nano banana 是结合了 Google 多个团队的项目成果。首先就是 Gemini 强大的世界知识与指令遵循能力,其次就是 Google 内部顶尖文生图模型 Imagen,所提供的极致图像美学与自然度追求。

香蕉也能变礼服?Google 真的做到了! 在最新一期谷歌开发者节目里,Google DeepMind 团队首次全面展示了 Gemini 2.5 Flash Image —— 一款拥有原生图像生成与编辑能力的最新模型。
谷歌这次又赢麻了! 神秘图像编辑模型 nano banana 被谷歌认领、正式改名为 Gemini-2.5-flash-image 后,热度仍居高不下,火爆程度丝毫不亚于 GPT-4o 掀起的「吉卜力热潮」。
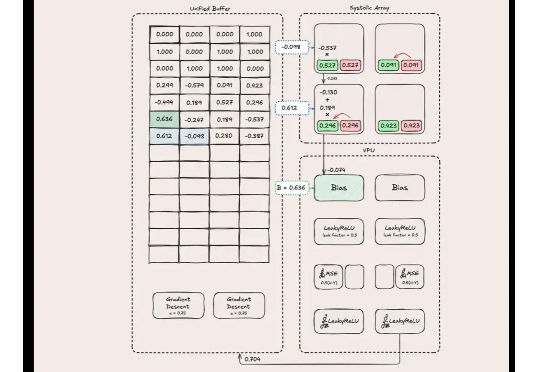
对于计算任务负载来说,越是专用,效率就越高,谷歌的 TPU 就是其中的一个典型例子。它自 2015 年开始在谷歌数据中心部署后,已经发展到了第 7 代。目前的最新产品不仅使用了最先进的制程工艺打造,也在架构上充分考虑了对于机器学习推理任务的优化。TPU 的出现,促进了 Gemini 等大模型技术的进展。
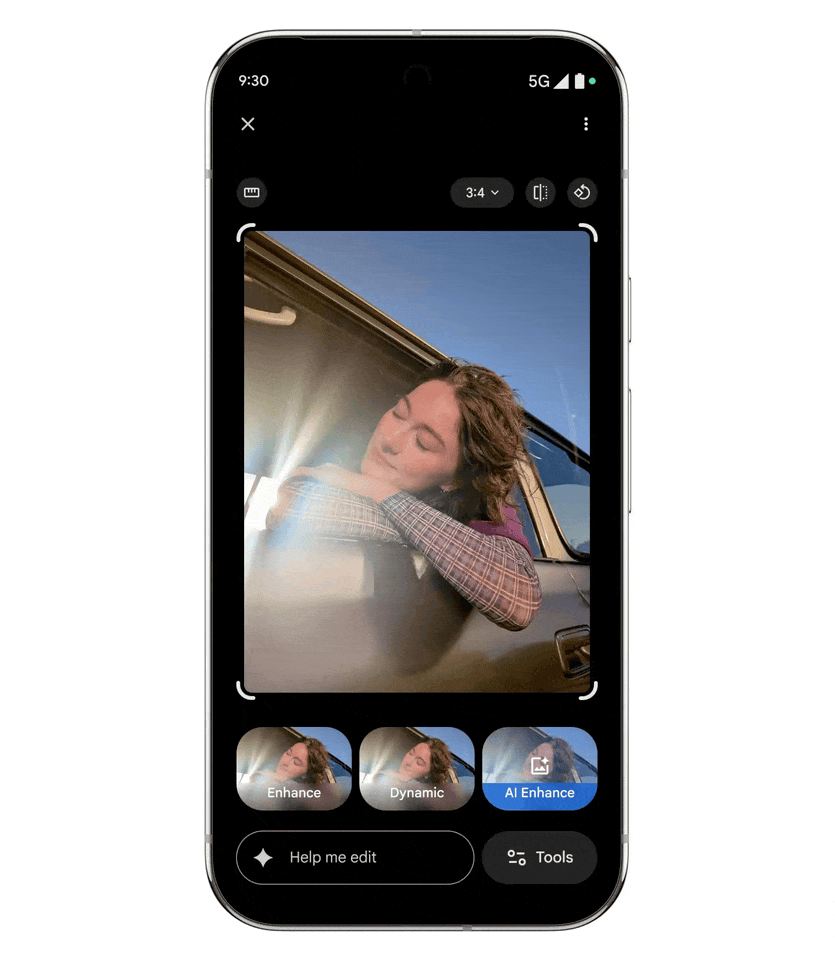
世界上最聪明的手机 Google Pixel,这次要连 P 图的活都帮你干了。 刚刚全新发布的 Pixel 10 系列手机,不仅能用 AI 手把手帮你拍照或者增强你拍的远距离照片,还支持全新的 AI 修图工具:只要动动嘴皮子,告诉 Gemini 你想要什么样的图,AI 就能自动帮你 P 好了。
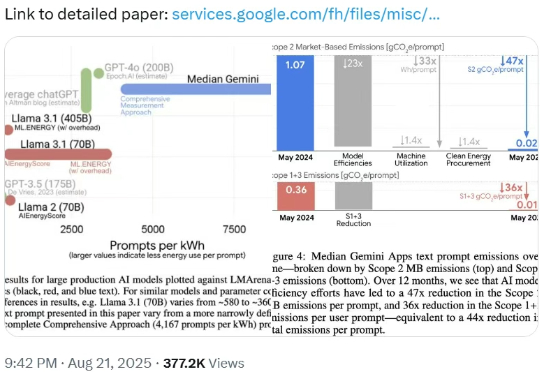
谷歌最近发布了一项关于其 AI 模型 Gemini 能源消耗的研究报告。
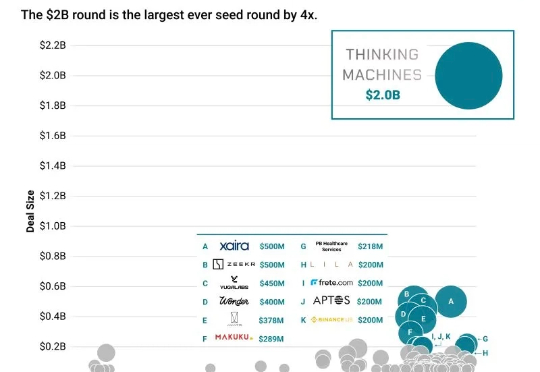
硅谷各个模型公司在这个季度,开始分化到各个领域,除了 Google Gemini 和 OpenAI 还在做通用的模型;Anthropic 分化到 Coding、Agentic 的模型能力;Mira 的 Thinking Machines Lab 分化到多模态和下一代交互。